

“WITHOUT BIG DATA ANALYTICS, COMPANIES ARE BLIND AND DEAF, WANDERING OUT ONTO THE WEB LIKE DEER ON A FREEWAY” – GEOFFREY MOORE
Entrati a pieno titolo nei trend topic di cui conoscere evoluzioni, curiosità e futuri scenari, i Big Data sono nel mirino non solo di multinazionali e grandi aziende che ne hanno giustificato l’importanza con la creazione di ruoli dirigenziali ad hoc, ma anche di PMI.
Ma da dove nasce l’attenzione delle aziende verso i Big Data?
Secondo Geoffrey Moore – consulente e scrittore americano – dalla “paura di ritrovarsi nella sorda oscurità del limbo digitale – del web – come renne spaesate in mezzo ad un’autostrada”.
Qual è l’humus di questa paura?
Il vagabondare senza meta precisa è un timore che cresce con una maggiore consapevolezza di come i Big Data rappresentino la nuova materia prima delle attività imprenditoriali, del business, citando Craig Mundie, Senior Advisor del CEO di Microsoft.
Sappiamo quindi che i Big Data sono importanti e imprescindibili per lo sviluppo attuale, ma soprattutto futuro delle aziende: per quale motivo?
Parafrasando lo scrittore indiano Ankala V. Subbarao: “Analizzare i dati significa fornire informazioni; rielaborare informazioni significa creare conoscenza e rielaborare la conoscenza significa dar vita alla saggezza.”
È chiaro, quindi, che i dati, e le informazioni che ne derivano, sono la fonte da cui nasce il vero sapere: un patrimonio culturale non fondato sulle opinioni ma su statistiche e algoritmi che variano a seconda degli input.
Da qui, la necessità di comprendere tutti gli aspetti della realtà in cui le imprese operano attraverso i Big Data, cogliendo tutte quelle informazioni non facilmente identificabili per orientare il business verso obiettivi strategici più puntuali.
Nell’ottica di concretizzare questa vision, Interlogica ha voluto ospitare un workshop sul tema.
Prima di raccontarvi il nostro approccio strategico, un po’ di storia.
COSA SONO I BIG DATA? A CHI DEVONO LA LORO ORIGINE?
Big Data. Due termini, nella lingua inglese, che apparentemente non accennano a nulla di straordinario – trad. letterale, grandi dati – ma nell’ultimo ventennio hanno plasmato l’immaginario collettivo, instillando una veloce associazione a volumi di informazioni, che una mente umana non può concepire né rielaborare.
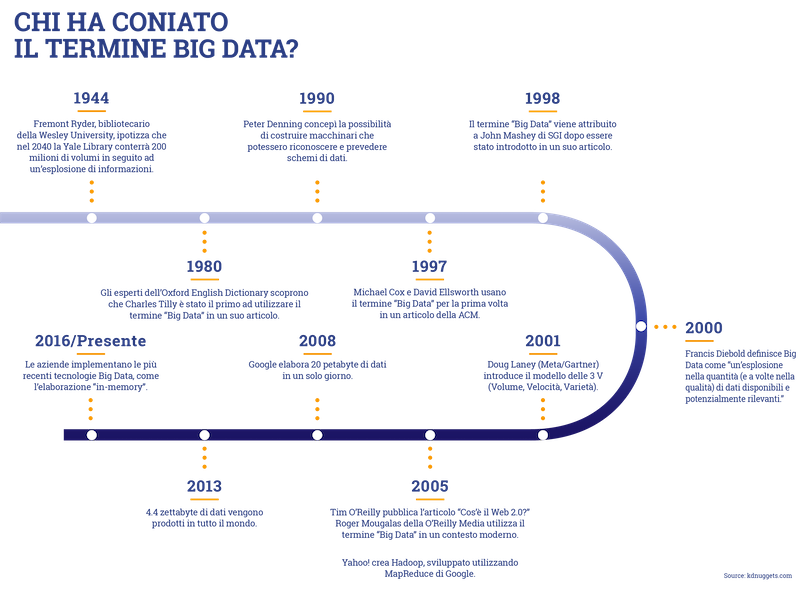
Ci si è accostati a tale concetto a causa di una ricerca del 1944, pubblicata da Fremont Rider, bibliotecario della Wesleyan University, la quale introduceva la concezione di “information explosion”.
Nello specifico, dato un raddoppio in dimensioni delle biblioteche americane ogni 16 anni, si stimava che nel 2040 la biblioteca di Yale avrebbe richiesto uno staff di circa 600 persone e oltre 10.000 km di scaffali.
Rider, però, non aveva considerato la digitalizzazione delle biblioteche, per questo parlava di un’invasione di informazioni – aggiungerei – in formato cartaceo.
Da qui fino al 2000 si sono via via susseguiti numerosi interventi, pubblicazioni e presentazioni di ricercatori e professionisti di diversi settori che hanno reso sempre più stringente la relazione tra Big Data e, i suoi aspetti quantitativi e qualitativi.
L’inizio del millennio ha segnato una vera e propria milestone nella reale comprensione di questo concetto: per la prima volta in un articolo del Times, l’autore – Francis Diebold – si riferisce ai “Big Data come un’invasione/esplosione in quantità, e talvolta in qualità, di dati disponibili e potenzialmente rilevanti”.
Dall’anno successivo il termine Big Data viene investito di ulteriore importanza con il primo conio – ad opera di Dough Laney – delle sue proprietà: le note 3V.
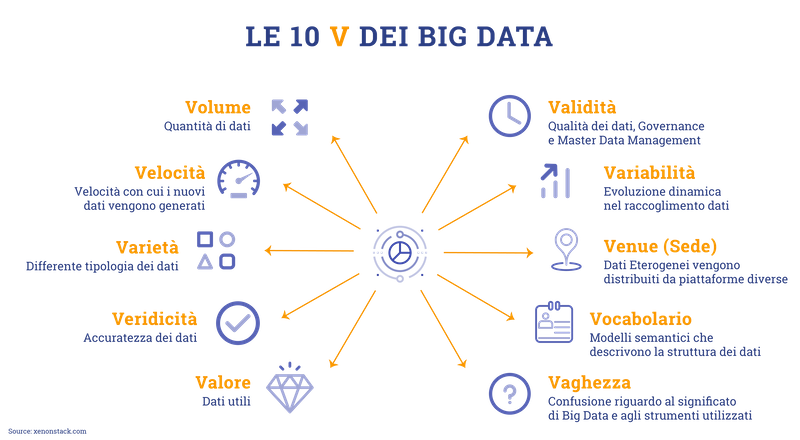
- Il volume descrive come l’unità di misura dei Big Data si sposti dai Terabytes a Zettabytes.
- La velocità fa riferimento alla velocità con cui i dati vengono generati.
- La varietà attiene al formato dei dati, in particolar modo alla transizione da formato strutturato ad uno destrutturato.
Dal momento che i Big Data provengono da fonti di varia natura, risulta complesso connettere ed estrarre tali dati e in seguito individuarne le variazioni – queste 3 fasi costituiscono il Big Data Ingestion – in sostanza, si fa riferimento al trasferimento di dati dal luogo in cui sono stati generati ad un sistema più accessibile che li possa conservare e analizzare.
Studi più recenti individuano un secondo conio che introduce una quarta V: quella della veridicità di questa tipologia di dati rispetto ad altri che spesso sono inconsistenti e, creano ambiguità e approssimazioni.
Tuttavia di recente si sono identificate altre V per un totale di 10.
IL GIRO DI BOA
Dalle riflessioni su queste caratteristiche, alcune aziende hanno cominciato ad attribuire notevole rilievo ai Big Data e al loro utilizzo, senza però trovare subito soddisfatte le loro esigenze pratiche, fino al 2005, anno che segna una nuova tappa fondamentale nella storia dei Big Data.
Questo è l’anno in cui appare sul mercato Apache Hadoop, ovvero un framework che supporta applicazioni distribuite che possono lavorare con petabyte di dati.
Per i Big Data inizia un nuovo corso: Hadoop rappresenta la risposta concreta alla necessità di applicazione reale dei Big Data ai differenti settori di mercato.
I primi a dimostrare interesse sono stati gli istituti creditizi e assicurativi: gli istituti bancari avevano necessità di valutare con maggiore precisione l’accesso al merito creditizio e le sue condizioni di concessione; mentre i secondi, intendevano adeguare il valore del premio assicurativo al reale rischio dell’assicurato di causare incidenti.
La potenzialità di ristabilire un equilibrio soprattutto nel pagamento del premio assicurativo, grazie alle analisi storiche e predittive più puntuali che i Big Data permettevano in questi settori, ha trovato una spinta propulsiva con l’introduzione sul mercato dell’Internet of things (IoT).
Attualmente anche le aziende del settore energetico sono fortemente orientate all’applicazione dei IoT ai Big Data.
Una tecnologia come l’IoT presenta maggiore applicabilità se alimenta i Big Data.
L’IoT richiede un innumerevole mole di sensori – o oggetti fisici – che captano dati di ogni tipo e li trasmettono ad un pannello di controllo che aggiorna e analizza in tempo reale tutte le informazioni raccolte. Questa tecnologia introduce quello che viene definito Real Time Analytics, ovvero l’accessibilità dei dati al momento della ricezione/produzione degli stessi dati.
LA VISION STRATEGICA
Questa opportunità ha permesso ad Interlogica di porsi al centro di una vision strategica grazie alla quale potrà mettere in relazione in ogni momento dati e informazioni di valore con i clienti delle aziende del canale B2B con cui stringe rapporti commerciali.
Il passaggio da Data Analytics a Real Time Analytics, accelerato anche dall’IoT, marca una fase cruciale dell’analisi e rielaborazione dei dati – Grandi Dati – perché si fornisce maggiore velocità e precisione alle statistiche predittive, rispetto al Data Mining* conosciuto negli anni precedenti.
Analizzare i dati in real time indubbiamente implica un vantaggio competitivo per tutte le aziende che intendono sfruttare trend innovativi e cercare sempre la leadership di settore.
Combinare l’adozione del Real Time Analytics sui Big Data con strumenti evoluti di Business Intelligence (BI)rappresenta la nuova frontiera per detenere la pole position nel proprio mercato, e non solo. Un ulteriore e importante vantaggio offerto ai player è la capacità di interrogare in modo combinato e flessibile strutture Big Data multi-vendor e strutture Data Lake.
Questo obiettivo è facilmente raggiungibile solo grazie alla fruizione di soluzioni end-to-end intuitive ma con funzionalità avanzate, indirizzate agli analisti: strumenti adeguati sia a profili esperti nell’analisi dei dati sia a quelli poco esperti e dal background prettamente commerciale per essere in grado di orientare il business.
Cogliere questa opportunità, non totalmente esplorata dai vari player del mercato, significa concorrere con forte anticipo alla spartizione di un mercato dalle ottime potenzialità, fonte da cui tutte le aziende sono obbligate ad attingere.
La nostra azienda ha compreso da tempo il valore della stretta connessione tra IoT e Big Data, ma soprattutto il valore di poter coniugare un potente strumento di front-end BI con il Real Time Analytics su differenti fonti Big Data/Data Lake.
Per questo, proponiamo soluzioni e occasioni di approfondimento che consentano ai nostri clienti di orientare la propria crescita su dati oggettivi significativi e porre attenzione su quei dati che non così facili da cogliere.
*serie di tecniche e metodologie dirette ad estrarre informazioni o conoscenza a partire da grandi quantità di dati, individuando correlazioni tra più variabili relativamente ai singoli individui


