
Si sente parlare ormai spesso di Big Data: la progressione esponenziale, con la quale è aumentata la capacità informatica di processare volumi ormai inimmaginabili di dati, ha permesso a scienza e business di portare il potere di calcolo e di immagazzinamento dei dati verso scale che, come vedremo, riusciamo a gestire ma fatichiamo a comprendere.
Ci muoviamo con assoluto agio tra terabytes e gigahertz, e persino la più famosa azienda informatica mondiale, Google, deve il suo nome al “Googol”, un titanico numero formato da un 1 seguito da cento zeri.
Ma la nostra mente è davvero in grado di comprendere l’immensità di giga, tera, peta, hexa ed altre impronunciabili quantità che riportano alla mente quelle improbabili fortune di Zio Paperone?
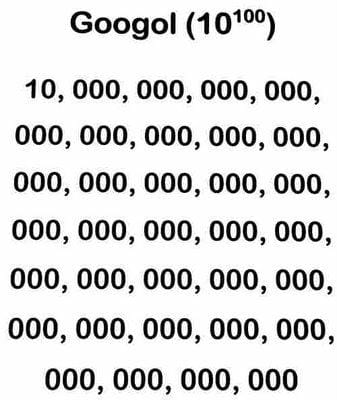
La risposta è decisamente no. Il nostro cervello è in grado di concepire quantità che arrivano fino alle migliaia, ma quando la cifra supera quella soglia, aumenta la difficoltà.
Facciamo una prova.
Ciascuno di noi nel suo pc ha ormai un disco rigido che ha una capacità di almeno un terabyte, ovvero 10^12 bytes, quindi 1.000.000.000.000 bytes, scrivendolo per intero.
Ok, ma quanto grande è davvero?
Supponiamo di scrivere ciascun byte contenuto nel nostro disco su un pezzo di carta della larghezza di un 1 cm. Se mettessimo in fila, uno dopo l’altro, questi frammenti di carta, quale distanza riusciremmo a coprire?
Ebbene, ne risulterebbe un “serpente” di carta che riuscirebbe a coprire la distanza Terra-Luna, andata e ritorno, per ben 14 volte.
O potrebbe avvolgere la circonferenza dell’equatore terrestre per più di 784 volte.
Se ogni byte fosse un essere umano, con 10^12 persone potremmo riempire 142 diversi sistemi solari uguali al nostro.
Se foste poi particolarmente annoiati, e decideste di voler passare il tempo trascrivendo uno a uno i bytes con una penna impieghereste lo stesso tempo che ci ha messo la razza umana ad evolvere dalla sua forma primitiva a quella attuale (circa 32 mila anni). Dubito che, arrivati alla fine, abbiate la voglia di controllare di averli scritti tutti giusti; fermo restando che, con ogni probabilità, tutto l’inchiostro esistente non sarebbe nemmeno sufficiente.
Eppure una simile quantità di informazioni sta comodamente nella tasca di una vostra giacca, e parlare di terabytes oggi non fa venire le vertigini a nessuno. Forse perché protetti dalla nostra stessa incapacità di comprendere l’immensità di certe cifre, non siamo spaventati dell’enormità di questi numeri. È come vedere solo alcuni alberi, senza cogliere la foresta.
ALTRI NUMERI INCONCEPIBILI: EXABYTE E PETABYTE
Ma ritorniamo ai nostri sistemi Big Data. Per definizione, essi sono sistemi che lavorano con un quantitativo di dati che non può essere contenuto in un normale elaboratore.
Quindi, sicuramente più di un terabyte di informazioni.
Vediamo quindi due tra i sistemi più famosi: alcune stime ipotizzano che Google e YouTube gestiscano rispettivamente 15 Exabytes e 75 Petabytes di dati. Un exabyte equivale a 10^18 byte o 1.000.000.000.000.000.000 bytes, se preferite.
Pensate che, se i bytes di Google fossero granelli di sabbia, ce ne sarebbero abbastanza da riempire due pianeti come la Terra.
Oppure, per vederla in un altro modo, Google contiene circa 4500 diversi libri per ciascun essere umano sulla Terra, e dal momento che la storia di ciascun individuo può essere raccontata in molti meno libri possiamo dedurre che Google è già in grado di ospitare qualsiasi informazione, anche la più irrilevante, di qualsiasi essere vivente nato su questo pianeta dal Big Bang ad oggi.
Inquietante vero?
La mole delle informazioni elaborate da YouTube è senza dubbio più contenuta, ma comunque sconfinata.
Se decideste di voler vedere tutti i suoi video, dovreste passare circa 5700 anni davanti al monitor, un intervallo di tempo ben più esteso dell’età della grande sfinge di Giza.
Se voleste convertire tutti i filmati e trasferirli su pellicola super 8, otterreste un nastro in grado di coprire la distanza che separa Mercurio da Venere.
PETABYTE, GOOGOL E GOOGOLPLEX A CONFRONTO
Eppure un Exabyte, e a maggior ragione un Petabyte, se confrontato con un Googol è talmente più piccolo che possiamo tranquillamente approssimarlo allo zero. O, da un punto di vista differente, l’intero archivio di Google occupa 0.000000000000000000000000000000000000000000000000000000000000000000000000000000001% di un Googol.
E, a sua volta, un Googol è microscopico a confronto di un Googolplex: un googolplex è un numero intero esprimibile con 1 seguito da un googol (10^100) di zeri: può anche essere scritto 10 googol.
Per capirci: un googol, per quanto grande sia, lo potete scrivere per esteso in una o due righe di un normale quaderno a quadretti.
È invece difficile avere un’idea di quante cifre abbia il googolplex (un googol ha 101 cifre), ma basta pensare che superano abbondantemente il numero delle particelle elementari presenti nell’intero universo conosciuto, che sono stimate essere tra le 10^79 e le 10^81.
La conseguenza di questo è il fatto che, mentre è relativamente semplice scrivere in notazione decimale un googol, non sarebbe materialmente possibile fare lo stesso col googolplex, neanche se ogni singola particella dell’universo fosse convertita in carta e inchiostro o memoria magnetica.
Ammettendo che fosse comunque possibile salvare l’elenco delle cifre che compongono un googolplex, anche il più potente computer oggi disponibile necessiterebbe di circa 3×10^85 anni per farlo. L’universo esiste da “appena” 1.38*10^10 anni.
Persino nella sua immensità, d’altronde, il Googolplex non è paragonabile ad altri numeri estremamente grandi, quali il Megistone e il Numero di Graham: per afferrare questo concetto, basta comprendere che, mentre il Googolplex può comodamente essere espresso in notazione esponenziale (quale 10^10^100, ad esempio), un numero come quello di Graham è assolutamente impossibile da riportare in questo genere di notazione.
Ma possiamo star tranquilli: a meno di non rimanere vittima di una singolarità tecnologica, simili cifre difficilmente arriveranno a farci compagnia nel quotidiano.


