
Big Data: a short introduction
Big Data and Analytics are two of the biggest revolutions that happened in the last few years in the digital world. It is a growing trend that will have an even bigger impact on our lives but it will also revolutionalize the way in which we do business.
Some of our daily actions generate a huge number of data: interconnected smartphones, clicks on websites, smart meters, IoT devices and vocal requests to Google, Siri or Alexa. These are massive volumes of miscellaneous data from different sources and with different formats which can all be analyzed in real-time: all this is Big Data.
Big Data is quite a new concept that still now struggles in getting a proper and standard definition. The first description of Big Data is linked to the size of data, whose starting point is measured in terabytes (1024 gigabytes), petabytes (1024 terabytes) and even more, using zettabytes (billions of terabytes). To give the concept some tangible sense, experts have divided it into 3 main relevant segments, calling them the 3V of growth for Big Data.
- Variety – all the information archived in Big Data are tremendously different and each one of them comes from a very specific source.
- Velocity – extreme speed is needed to archive, save and catalog such an extended amount of information.
- Volume – technological solutions are needed to allow to have all the massive dimensions (from a bytes perspective) of Big Data managed.
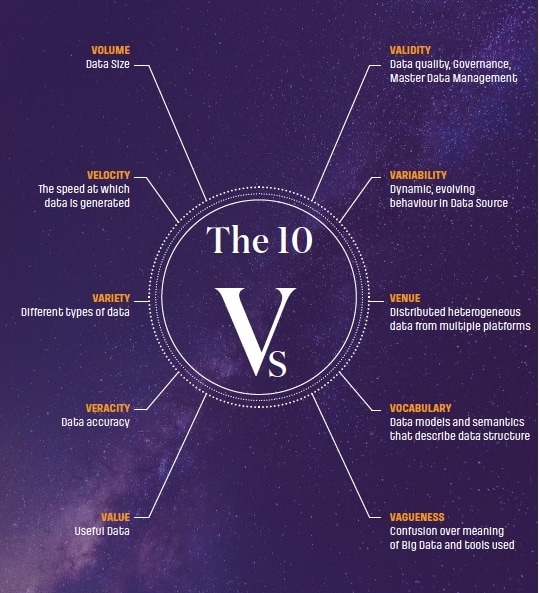
These fundamental features have now been divided into some further 10 segments – the 10V of Big Data – to describe the whole concept in full detail.
When we talk about Big Data we need to understand the changes that they involve: from the data-gathering process to the technologies supporting the lifecycle of data and the development of new competencies for valorizing the single datum. Managing and analyzing Big Data requires using appropriate technologies and having professional experts who can optimize availability and usefulness. Hence why the Data Scientist becomes a key figure in the process.
The information gathered from the analysis of such data helps to direct the business actions: marketing experts can then create strategic campaigns, health workers can easily identify epidemics and environmentalists can fathom future sustainability and so on.
Seeing all this from a market perspective, it is then possible to obtain a huge competitive advantage thanks to the ability to make prompt and well-informed decisions – this works for big organizations but it also works for small and medium companies.
According to a report published by Assintel about ICT market trends in March 2019, a growth of 1.6% is expected to happen in Italy for the whole year. The incremental trend is guided mainly by big and medium enterprises which are investing in technologies known as “Innovation Accelerators”, such as Internet Of Things, Artificial Intelligence, Big Data and Analytics, which are evolving at a very fast pace.
Comparing such info with a market that is globally and constantly growing by 1.4 billion Euro, the Italian situation of Big Data is definitely not rosy. The biggest percentage of investments comes from big companies. A third of these companies have introduced competencies in Machine Learning, and 44% use Real-Time or Near Real-Time Analytics. 56% are already employing Data Analysts, 46% have Data Scientists and 42% are Data Engineers.
Only a very tiny percentage of medium and small organizations have decided to start Big Data Analytics projects. This is quite a depressing fact considering that the economic market is mainly led by those medium and small organizations.
The link between Big Data and Artificial Intelligence
The expression “Big Data” is the popularisation of Machine Learning techniques: computers work on massive amounts of data to understand links and tendencies which human beings fail to see. This explains all the big discoveries we have now achieved in the last few years – Kenneth Cukier – Senior Editor Digital Products, The Economist.
As already highlighted before, every single organization can access a big amount of data: information about the business, from the web, social media, IoT sensors, and from other sources which are now extremely important for gathering details used to help the business grow. The simple gathering or access to data, without implementing the correct analysis, produces no results and ends up in being just a huge pile of raw data.
To transform all these data into something very useful we need to synchronize technologies. The connection between Big Data and Artificial Intelligence is fundamental to transform the initial data into information that can predict and guide us toward more effective decisions.
The automation of decisions has to absolutely go through the merge of technologies to be agile and fast to satisfy the market of today.
The center of the process is to become a data-driven organization, a situation that is often happening in big realities where decision-making processes are driven by more refined data.
This allows to have decisions reached in a short time and they are based on the robustness of objective and systematic evaluations.
Up till now, companies have never really given much attention to understand processes and clients’ behaviors and have never measured nor used the data they had in a satisfactory way. This is the main reason why small and medium size companies deeply believe Big Data is something quite useless.
How can raw data be transformed into something which gives added value to the business?
Many organizations are now working on how to transform “raw data” in high potential AI fuel. Info gathering, archiving and Big Data elaboration still suggest some significant challenges for all those firms who cannot afford to employ experts who will look after it.
Analytics on Big Data allows to efficiently optimize many different business aspects, for example helping and increasing rapidity in how to analyze and visualize big amounts of data, something which constitutes the first fundamental step towards the appreciation of Big Data.
It is now important to clarify two concepts that are usually associated with one another: Big Data is the raw material whilst Artificial Intelligence (AI) provides the tools to manage and better understand it.
There are different uses that result from the Big Data – Artificial Intelligence interaction: we can analyze customer sentiment and help marketing to drive focused actions; market trends can be identified before they are even born so the company can be driven towards a strategic decision-making process, competition can be assessed, analyzed and studied too and much more.
The totality of big organizations adopt descriptive Analytics but many of these companies are also experimenting an evolution toward Predictive, Prescriptive and sometimes Automated Analytics logic. These are ways of using Big Data to foresee or simulate future scenarios in an automated way. The transformation happens by techniques of Machine Learning and Deep Learning which habilitate types of analysis of Real-Time Analytics and Artificial Intelligence.
Lesson Learnt
Here at Interlogica we create solutions for managing, analyzing and visualizing (structured and unstructured) Big Data from every existing database and Data Lake. It is an opportunity to further explore data and define the correct architecture that our clients need.
Here are some important examples of how we effectively helped some clients to extrapolate value from the data they had, going through some processes, technologies and competencies in Analytics and Artificial Intelligence.
Big Data Analysis fot Energy Sector
.

GOAL (First Project)
A platform for the estimate of clients’ switch out.
CONTEXT
A very important multi-utility company in the energy sector decided to start an innovation project with us about Big Data through two main projects.
The first one was studying the switch-out rate of its clients to maximize Customer Retention.
CHALLENGE
We had to understand the factors linked to the reasons why customers were switching to other companies through the analysis of the company’s database, insight research on their clients, and by starting new commercial and marketing activities.
SOLUTION
We created a tool developed on Machine Learning techniques that allow us to analyze a plethora of anonymous info associated with clients, such as personal data, the history of contracts and subscribed offers and the interactions the clients had with the company itself (complaints, info requests or marketing activities).
We used such data for every client to understand the possible risk of annulling the contract in the near future, in an automatized way. The multi-utility has then associated all the anonymous info to the real clients.
The Machine Learning algorithms we used are Random Forest which allows to determine decisional factors (for example the increase of energetic bills) so offers can be adjusted and developed for every single client. Also, more correct estimates about cost/advantages to determine the right amount of investment which can be calculated.
.

GOAL (Second Project)
Creating a platform for estimating electrical usage.
CONTEXT
Big Data and Artificial Intelligence have intertwined also in this second project which is about increasing the efficiency of the forecast process of electric consumption.
CHALLENGE
Optimizing the buying process of the electrical energy whilst reducing the costs for the multi-utility and the energetic waste. Reducing the margin error in forecasting consumption is a crucial point in this optimization process.
SOLUTION
We created a platform that analyzes real-time electrical consumptions and weather forecasts: it combines the data with other info about consumers and calendars. These data then get structured in a database that uses the amount of data to train predictive models for electrical consumption.
These are decomposition models of historical data combined with Ensemble Learning methods automatically selected by the platform. It has been provided with a decisional model which allows selecting the more adequate algorithm to foresee the electrical consumption of the type of consumer and the period of the year in which the forecast needs to be made.
To allow the client to interact in an agile way with the data and to visualize the consumptions forecast by the platform we gave them an interactive dashboard realized with the help of Esplores.
Models have been elaborated with anonymized data for this project too.
Big Data for Legal Invoicing
.

GOAL
Creating a platform to manage the flow of electronic invoices.
CONTEXT
One of the biggest players in Italy for certification authority has started some investments in innovation projects using Big Data so the flow of electronic invoices of clients can be managed (the system is designed to work supporting 500 invoices per second).
CHALLENGE
To create a flow of automatic management for invoicing which allows to archive and analyze massive amounts of data.
SOLUTION
After a careful evaluation of the needs and expectations of clients, we decided to use a technology called Apache Kafka combined with a Hadoop cluster specifically designed to archive and analyze big quantities of non-structured data in a distributed calculation environment.
All these sets of data are divided into an Oracle database which allows a real-time elaboration of metadata. The sets of data will remain there for three years as we estimated the analysis of almost a petabyte of data will be carried out in such a timeframe.
Natural Language Processing applied to Automatic E-mail Dispatching
.

GOAL
Automatic sorting of PEC (Certified) emails
CONTEXT
A fourth project in which we were involved was developing an Artificial Intelligence platform to automatize the sorting of certified emails for a Financial Services company.
CHALLENGE
Improving, quickening and automatizing the analysis functions of the text to identify the recipient of the emails in an automated way.
SOLUTION
We decided to use the Natural Language Processing (NLP) method, a computer processing of the natural language paired with Machine Learning techniques.
For such a project, our Data Science team has analyzed a cluster of mail to build a classification model of the text.
These models allow classifying the incoming emails according to their context (sender, subject, body) automatically forwarding them to the right group of work or recipients.
The platform allows the creation of automated emails to reply in the context of the email received.
The client also has the chance of correcting some inaccuracies that might happen in the automatic sorting of communicating the right recipient to the platform; the algorithms of the Artificial Intelligence modify themselves automatically according to the new info, incrementing the precision of the platform itself.
The result is an accurate and trustworthy categorization of emails which translates into fewer mistakes and time wasted from an employee perspective.
To summarise:
- It uses NLP AI technology.
- It automatically classifies emails as soon as they come in.
- It generates an automated response according to the correct context of the email.
- It reduces mistakes and helps to save time for employees.
You might also like:
Big Data, the raw material for 4.0 Business
Big Data transforms Business Intelligence and Analytics platforms
Artificial Intelligence, beyond Robotic Process Automation


